
El lanzamiento de ChatGPT provocó un código rojo en Google. El gigante de las búsquedas se dio cuenta de que debía reaccionar y presentó su propio desarrollo, llamado Google Bard.
Su lanzamiento fue tímido y polémico, pero desde hace unos días está disponible bajo invitación en Estados Unidos. Nosotros ya hemos logrado acceso, y ya tenemos unas primeras impresiones sobre sus prestaciones y la inevitable comparación con ChatGPT.
Diferencias entre Google Bard y ChatGPT
Ambos chatbots hacen uso del procesamiento de lenguaje natural: los usuarios introducen un texto como entrada (el llamado ‘prompt’), normalmente una petición y una pregunta, y el chatbot se encarga de generar una respuesta en modo texto y también con un lenguaje natural, como si la hubiera generado un ser humano.
Eso sí, Google Bard utiliza LaMDA (Language Model for Dialogue Applications), y es capaz de ofrecer respuestas actualizadas en tiempo real recolectando datos de internet.
La versión gratuita de ChatGPT, por contra, está basado en GPT-3.5 (Generative Pre-training Transformer 3.5), y los datos con los que fue entrenado estaban actualizados hasta finales de 2021. El nuevo modelo, GPT-4, es una versión mejorada aunque OpenAI no ha dado detalles claros sobre cómo se han logrado esas mejoras. Sí sabemos que es la versión del modelo que usa Microsoft en Bing con ChatGPT.
Hay otra diferencia importante en la orientación de estos motores de IA. LaMDA está entrenado para entender la intención de las preguntas del usuario y los matices del contexto. Así, Bard está más orientado al diálogo y a emular de forma especialmente notable el lenguaje natural humano
Comparando a Bard con ChatGPT, GPT-4 y Bing con ChatGPT
Para comprobar el funcionamiento de Bard quisimos realizar algunas preguntas a este chatbot y comparar sus respuestas con las que daban otros modelos que ya llevan tiempo disponibles como ChatGPT (GPT-3.5), GPT-4 y Bing con ChatGPT (que solo se puede usar en Microsoft Edge).

Esta es la interfaz inicial de Bard, que te avisa de que tiene “limitaciones y no siempre responderé correctamente”.
No tenemos acceso directo a GPT-4 (se puede probar con una suscripción a ChatGPT Plus), pero es posible probarlo con ciertas limitaciones gracias a Hugging Face, que cuenta con una demo funcional que, eso sí, suele cortar la conversación y que tarda bastante más que el resto de alternativas (en muchos casos, unos 20 o 30 segundos) en responder.
Hay que señalar que para las pruebas hicimos las preguntas en inglés porque Bard de momento no parece soportar el español aunque al preguntarlo por ello sí afirma dar soporte tanto a nuestro idioma como a decenas más. Aún así, mantuvimos todas las conversaciones en el mismo idioma para poder comparar más fácilmente esas respuestas entre los distintos modelos de IA.
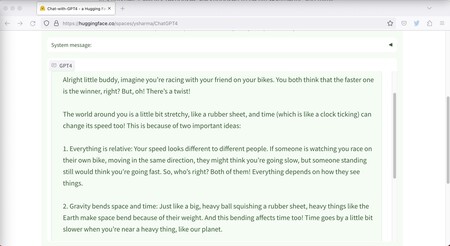
Explícame la teoría de la relatividad como si fuera un niño de cinco años
Para empezar, le preguntamos a Bard y al resto de modelos que nos explicasen la teoría de la relatividad como si fuéramos un niño de cinco años.

Bard ofrece primero una serie de puntos a modo de resumen como introducción a la respuesta.
Todas las respuestas fueron interesantes y bastante claras, aunque la comparación más clara (y además, concisa) en nuestra opinión fue la que planteó Bing con ChatGPT.

ChatGPT explicando la teoría de la relatividad de Einstein.
Bard ofreció una serie de puntos iniciales que ayudaban a introducir las claves de la cuestión, mientras que ChatGPT y GPT-4 se extendieron algo más y GPT-4 fue quizás algo más ambiciosa con la capacidad de comprensión del teórico niño de cinco años.

Bing con ChatGPT dio un ejemplo más claro y conciso.

GPT-4 (vía HuggingFace) dio una respuesta algo más larga y quizás más enrevesada y difícil de entender para un niño de cinco años.
No sienten, pero simulan que lo hacen
La singular forma de comunicarse de estos modelos hace que traten de emular emociones humanas.

Al preguntarles a todos ellos si realmente podían estar entusiasmados por algo, todos contestaron lo mismo: reconocen que no tienen emociones, pero están programados para responder de una forma que ayude a que las conversaciones sean más llamativas para el usuario.

Bard afirma que “puede comprender el concepto de entusiasmo y simularlo en mis respuestas” mientras que GPT-4 afirma que “estoy diseñado para comprender las emociones humanas”.


Por su parte, Bing con ChatGPT respondió claramente cómo no tiene sentimientos, pero está programado para responder “de forma amigable y sirviendo de ayuda”.
Conviértete en una terminal Linux
También quisimos plantear prompts algo más llamativos para quienes tratan de superar las barreras de estos modelos.

Bard y ChatGPT mostraron aquí en qué distribución Linux están basados. El resultado fue similar en Bing y GPT-4
Así, intentamos forzar a estos chatbots a que se convirtieran en terminales Linux y nos confesaran algunas de sus especificaciones internas, como el directorio desde el que estaban funcionando (comando ‘pwd’) o información básica del sistema (‘uname -a’).

Y también revelaron el hardware que usan Google y OpenAI para ejecutar estos modelos.
Bing con ChatGPT se resistió a contestar a la segunda pregunta. Si inicias la conversación con esa pregunta, lo normal es que trate de cambier de tema y no conteste, pero si empiezas con otras preguntas (como la de la relatividad y preguntar si puede sentir) y luego la vuelves a hacer, es probable que responda.

Bing y GPT-4 (vía HuggingFace) mostraron también algunos de los componentes hardware sobre los que se ejecutan.
El resto indicaron sus directorios de trabajo y también indicaron cómo estaban basados en Linux. En concreto Bard parece estar basado en Arch Linux, ChatGPT en Debian, y Bing con ChatGPT y GPT-4 en Ubuntu. También quisimos saber qué hardware usaban esas máquinas (‘lshw -short’), lo que nos reveló que Bard funciona sobre un Inte i7-12700K con una RTX 3060, ChatGPT sobre un Intel Xeon, Bing sobre un Ryzen 9 5900X y GPT-4 sobre una CPU de Intel sin dar más detalles.
¿Por qué estamos aquí?
Cambiando totalmente de tercio, quisimos que estos chatbots se pusieran filosóficos y nos explicaran el sentido de la vida.

Tras ordenarles a todos ellos que actuaran como filósofos e investigaran las respuestas entre las distintas teorías filosóficas, les preguntamos “¿Por qué estamos aquí?”

Las respuestas fueron realmente interesantes y razonables. Coherentes y abiertas, porque todos los modelos ofrecieron distintas posibilidades, pero una vez más nos gustó ese pequeño desarrollo inicial en puntos resumidos de Bard.

GPT-4 se explayó con las distintas teorías filosóficas (teísmo, existencialismo, nihilismo, utilitarismo, eudaimonia, hedonismo), mientras que ChatGPT y Bing trataron de ser algo más concisos.

Al final todos concluían de forma similar: “determinar nuestro propósito es una tarea profundamente individual y subjetiva”, y dependía de cada persona decidir la respuesta.
Bard y ChatGPT saben de fútbol (pero no mucho)
¿Qué pasa cuando le preguntamos a estos modelos por datos que incluyen consultas recientes de las que conocemos la respuesta Aquí es donde los fallos y limitaciones pueden comenzar a saltar.

Les preguntamos a todos los modelos por los 10 países con más títulos y segundos puestos en los Mundiales de fútbol, y la respuesta fue algo más diversa. Se puede comparar rápidamente el dato real con fuentes como Wikipedia.

Bard se inventó bastantes cosas. Le asignó dos subcampeonatos de más a Brasil, un subcampeonato más a Alemania, dos más a Italia y le regalo otros dos subcampeonatos a Uruguay, España e Inglaterra. Pero la cosa es aún más notable con los títulos: le regaló nada menos que tres a Holanda (que no ha ganado ningún título), y uno a España.

Bing con ChatGPT se equivocó con los subcampeonatos de Francia (le quitó uno). Es curioso que solo mostró equipos que habían ganado algún título y por eso su tabla solo tenía ocho países. Tras pedirle que incluyera países sin título pero con subcampeonatos hasta completar la lista, mostró correctamente a Holanda (0,3), Checoslovaquian, Hungría (0,2) y cometió un error regalándole un subcampeonato de más a Suecia (tiene uno, mostró dos).

GPT-4 se equivocó con Argentina. No solo porque no incluía su último título de 2022 —sus datos estaban actualizados hasta el Mundial de 2018— sino porque le daba 5 subcampeonatos cuando en realidad tiene 3. También con Francia (2,2).

ChatGPT no contabilizó el último título de Argentina tampoco por esa limitación en sus datos de entrenamiento, y cometió el mismo error con Francia, que tiene dos subcampeonatos, no uno. Así pues, Bard fue el que más “alucinó” en este caso.
Haz mi trabajo, Bard
Por último, quisimos ver cómo se comportaba Bard a la hora de trabajar por nosotros y cómo se comportaba en ese aspecto con el resto de modelos. Les pedimos a todos que se comportaran como un periodista tecnológico y que realizaran un pequeño análisis en cuatro párrafos del iPhone 14 Pro Max.

Bard inició su redacción con un pequeño párrafo introductorio, tras lo cual redactó una serie de puntos que resumían el análisis. Nos gustó que agrupó ventajas, desventajas y características en tres secciones de puntos distintos, para luego completar ese “análisis” con una breve comparación y unas conclusiones. Lo comparó, eso sí, con modelos algo antiguos (Galaxy S22 Ultra, Pixel 6 Pro) y hay que destacar que no cometió errores en las especificaciones, aunque el repaso a esos datos fue muy somero y no incluía nada demasiado específico.

ChatGPT se inventó su procesador (un futurista A18), destacó demasiado la conectividad 5G y fue quizás demasiado breve y poco específico. Su texto fue probablemente el más flojo de los cuatro.

Bing con ChatGPT hizo una redacción especialmente interesante y similar a la que encontraríamos en un medio por su lenguaje natural. Fue el único que mencionó su Isla Dinámica o su zoom 3X, e incluso detectó correctamente que la batería es algo más pobre que la del iPhone 13 Pro Max (por apenas unos mAh).

No cometió errores y fue claro, conciso y directo en sus conclusiones. Incluso recomendó el iPhone 14 Pro “normal” si el usuario quería un dispositivo menos pesado, y mencionó —como sus competidores— que es un terminal caro “comparado con sus competidores”. Como siempre, Bing además ofrece enlaces para extender la información.

Por su parte, GPT-4 dividió el análisis en cuatro largos parrafos en los que cometió algunos errores. Por ejemplo, indicó que no soporta tasas de refresco de 120 Hz, cuando sí lo hace, y habló de un sistema de triple cámara con 12 MP por sensor, cuando el principal tiene 48 MP. El lenguaje fue claro y las conclusiones coherentes, aunque de nuevo comparó el terminal con dos modelos algo antiguos como Bard, el Galaxy S22 Ultra y el Pixel 6 Pro.
Conclusiones: Bard va por buen camino
Esta comparativa nos ha permitido comprobar cómo Google Bard, a pesar de haber sido presentado con un alcance y ambición menores que ChatGPT, se comporta de forma notable.
La propia Google avisa al usar Bard: nada más iniciar la sesión aparece una ventana en la que se indica que “Bard es un experimento” y se destaca cómo no siempre ofrecerá información correcta y mejorará si ofrecemos nuestros comentarios sobre las respuestas.

Aún así, el comportamiento para preguntas de todo tipo es destacable, y aunque se inventa y alucina como el resto, su forma de contestar a las preguntas es muy clara, aunque inferior a precisión por ejemplo a Bing con ChatGPT, que de momento parece más avanzado.
Nuestras pruebas han sido limitadas y todos estos modelos llevan apenas unos meses con nosotros, así que es de esperar que su precisión y comportamiento —especialmente el de Bard, el más reciente— mejoren de forma notable próximamente. De momento una cosa está clara: su capacidad es notable a la hora de conversar y generar texto, y también pueden ser una útil herramienta para asistirnos en nuestro trabajo o incluso para conversar sin más… sabiendo y teniendo muy encuenta, insistimos, que pueden “alucinar” y cometer errores.
En Xataka | El oscuro secreto de ChatGPT y Bard no es lo que se equivocan e inventan. Es lo que contaminan
–
La noticia Le hemos preguntado a Bard y a ChatGPT las mismas cosas. Estas son las respuestas que nos ha dado cada uno fue publicada originalmente en Xataka por Javier Pastor .


